Table of Contents
I had an absolute breakthrough tonight regarding how the WE32101 MMU handles caching. In fact, when I implemented the change, my simulator went from having 108 page miss errors during kernel boot, to 3. The cache is getting hit on almost every virtual address translation, and because of what I learned, the code is more efficient, too.
The key to all this was finally looking up 2-way set associative caching (see here, here, and here), which the WE32101 manual identifies as the caching strategy on the chip. Once I read about it, I was enlightened.
Remember how I was complaining about not enough bits being used for the tag? It turns out this is exactly by design. The tag is used in the cache to identify that you’ve found the right segment or page descriptor, yes, but it’s not used to index them. Instead, the “missing” bits are used as an index.
The way n-way set associative caching works is that some bits are used as a tag, and some bits are used as an index into the cache. You use that index to find a set of n entries. The SD cache is technically a 1-way set associative cache, because there’s only one entry in each set. Bits 17-19 are used to form an index into one of the 8 available cache slots. The tag is compared against the value in the slot. If they match, it’s a cache hit. If not, it’s a cache miss.
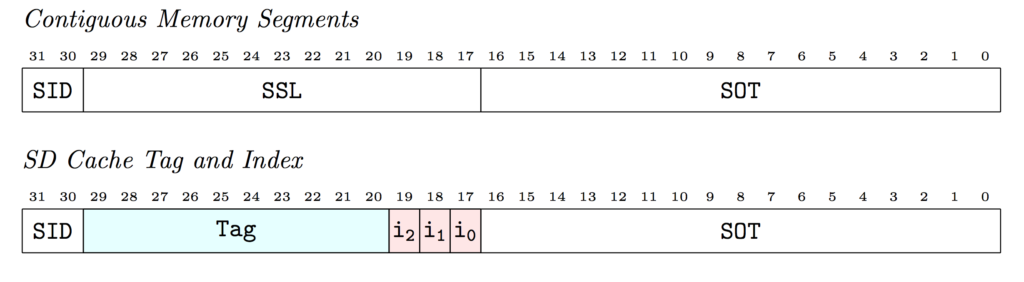
In the example above, you can see that the SSL part of a virtual address for a contiguous segment is broken into a 10-bit tag, and the three bits left over that I thought were “missing” are actually used as as an index.
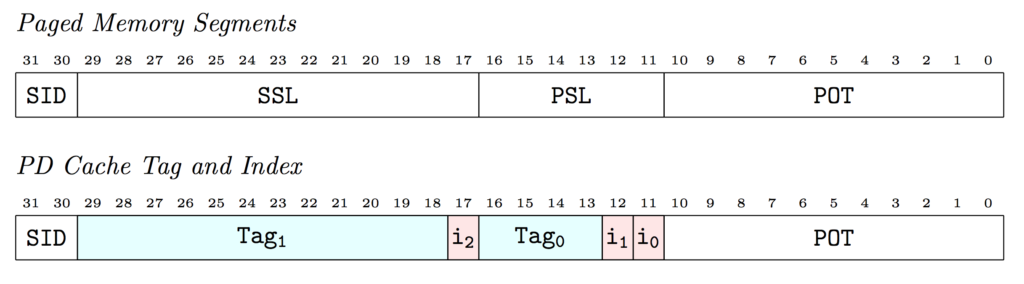
The PD cache works similarly, except it’s 2-way set associative. There’s a “Left” and “Right” entry in each cache slot. You compare your tag against each entry to see if you have a match. When writing into the cache, you pick which one to use by examining the Most Recently Used bit of the left cache entry, which flips back and forth between 1 and 0 depending on whether left or right entry has been replaced most recently. In this way, each set in the cache is itself a Least Recently Used cache.
Once I figured this out, it was a breeze to implement. In fact it
simplified the code, and made look-ups a lot faster. I was doing an O(n)
linear cache scan before, now it’s O(1).
The darn 3B2 simulator still doesn’t boot all the way, but every time I find and fix a bug, I know I’m getting closer.
Comments