I’m fairly happy with my parsing and tokenizing code now. I wanted to give a little breakdown of how it works.
The over-all goal here is to take a command from the user in the form:
C NNNN [(NN)NN [NN NN NN NN NN ... NN]]
where C is a command such as “E” for Examine, “D” for Deposit, etc.,
and store it in memory, tokenized and converted from ASCII to binary.
I wanted to give the user flexibility. For example, numbers do not
need to be zero-padded on entry. You should be able to type E 1F and
have the monitor know you mean E 001F, or D 2FF 1A and know that you
mean D 02FF 1A.
I wanted whitespace between tokens to be ignored. Typing "E 1FF" should
be the same as typing "E_______1FF___" (please mentally replace the
underscores with whitespace!)
And finally, I wanted to support multiple forms of commands with the same
tokenizing code. The Examine command can take either one or two 16-bit
addresses as arguments—for example, E 100 1FF should dump all memory
contents from 0100 to 01FF. But the Deposit command takes one 16-bit
address and between one and sixteen 8-bit values, for example D 1234 1A 2B 3C to deposit three bytes starting at address 1234.
So I decided I’d reserve 20 bytes of memory in page 0 to hold the tokenized, converted data.
- Byte 0 stores the number of arguments entered, not including the command itself
- Byte 1 stores the command, for example “E” for Examine or “D” for Deposit.
- Bytes 2 and 3 store the first argument, which is always a 16-bit address value.
- Bytes 4 and 5 store the second argument, which is sometimes a full 16-bits, and sometimes only 8-bits occupying byte 4.
- Bytes 6 through 20 are always 8-bit values.
Each implemented command then knows how to use this parsed data to fulfill its operation.
[An aside: Using page zero for this is controversial in my mind—21 bytes is a lot of space to use, and page zero is precious, so I will move it to page 2 at a later date. But it will work the same, just a change in addressing mode from Zero Page,X to Absolute,X would be required.]
How It’s Implemented
The implementation is fairly straightforward. Here’s a very rough flowchart with some details elided:
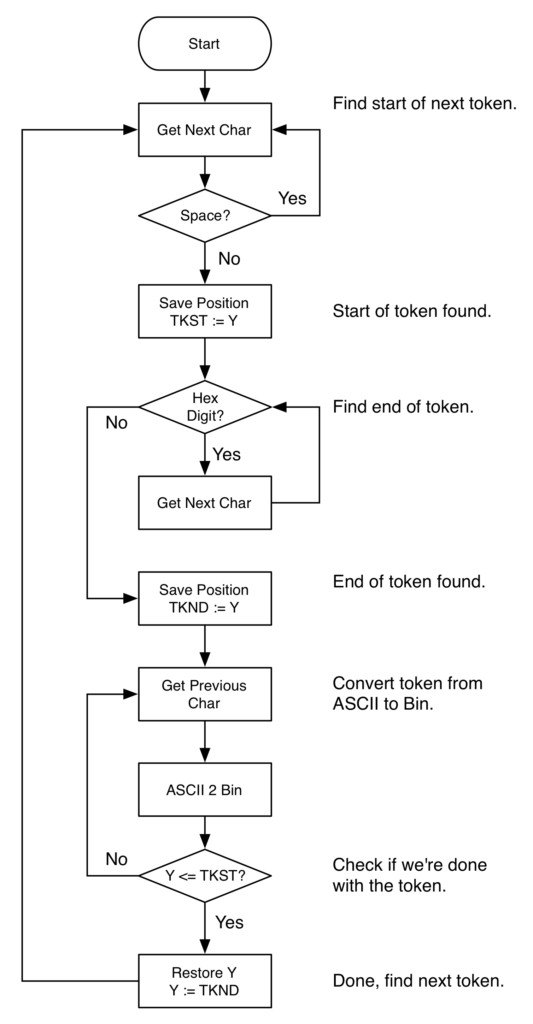
In general, the idea is to start at the beginning of IBUF, the input buffer, and scan until the start of a token is found. This location is then stored in TKST. Next, we continue scanning until the end of the token is found. The end is stored in TKND. Once it is, we walk the token backward, one character at a time, converting it from a hexadecimal ASCII representation into a number. Once we’ve reached the start of the token (or we’ve done 4 characters, whichever comes first), we know we’re done with the token. We jump back to TKND and start the process over again.
We do this until either:
- The buffer is exhausted, or
- We’ve scanned 17 arguments, total
whichever comes first. At that point, we fall through and start executing whatever command has been decoded.
The code is below.
;;; ----------------------------------------------------------------------
;;; Parse the input buffer (IBUF) by tokenizing it into a command and
;;; a series of operands.
;;;
;;; When the code reaches this point, Y will hold the length of the
;;; input buffer.
;;; ----------------------------------------------------------------------
PARSE: TYA ; Save Y to IBLEN.
STA IBLEN
BEQ EVLOOP ; No command? Short circuit.
;; Clear operand storage
LDY #$10
LDA #$00
@loop: STA OPBASE,Y ; Clear operands.
DEY
BPL @loop
;; Reset parsing state
LDX #$FF ; Reset Token Pointer
LDA #$00
STA TKCNT ; Number of tokens we've parsed
STA CMD ; Clear command register.
TAY ; Reset IBUF pointer.
;;
;; Tokenize the command and operands
;;
;; First character is the command.
LDA IBUF,Y
STA CMD
;; Now start looking for the next token. Read from
;; IBUF until the character is not whitespace.
SKIPSP: INY
CPY IBLEN ; Is Y now pointing outside the buffer?
BCS EXEC ; Yes, nothing else to parse
LDA IBUF,Y
CMP #' '
BEQ SKIPSP ; The character is a space, skip.
;; Here, we've found a non-space character. We can
;; walk IBUF until we find the first non-digit (hex),
;; at which point we'll be at the end of an operand
STY TKST ; Hold Y value for comparison
TKNEND: INY
CPY IBLEN ; >= IBLEN?
BCS TKSVPTR
LDA IBUF,Y
CMP #'0' ; < '0'?
BCC TKSVPTR ; It's not a digit, we're done.
CMP #'9'+1 ; < '9'?
BCC TKNEND ; Yup, it's a digit. Keep going.
CMP #'A' ; < 'A'
BCC TKSVPTR ; It's not a digit, we're done.
CMP #'Z'+1 ; < 'Z'?
BCC TKNEND ; Yup, it's a digit. Keep going.
;; Fall through.
;; Y is currently pointing at the end of a token, so we'll
;; remember this location.
TKSVPTR:
STY TKND
;; Now we're going to parse the operand and turn it into
;; a number.
;;
;; This routine will walk the operand backward, from the least
;; significant to the most significant digit, placing the
;; value in OPBASE,X and OPBASE,X+1 as it "fills up" the value
LDA #$02
STA OPBYT
;; Token 2 Binary
TK2BIN: INX
;; low nybble
DEY ; Move the digit pointer back 1.
CPY TKST ; Is pointer < TKST?
BCC TKDONE ; Yes, we're done.
LDA IBUF,Y ; Grab the digit being pointed at.
JSR H2BIN ; Convert it to an int.
STA OPBASE,X ; Store it in OPBASE + X
;; high nybble
DEY ; Move the digit pointer back 1.
CPY TKST ; Is pointer < TKST?
BCC TKDONE ; Yes, we're done.
LDA IBUF,Y ; Grab the digit being pointed at.
JSR H2BIN ; Convert it to an int.
ASL ; Shift it left 4 bits.
ASL
ASL
ASL
ORA OPBASE,X ; OR it with the value from the
STA OPBASE,X ; last digit, and re-store it.
;; Next byte - only if we're parsing the first two
;; operands, which are treated as 16-bit values.
;;
;; (Operands 2 through F are treated as 8-bit values)
LDA TKCNT ; If TKCNT is > 1, we can skip
CMP #$02 ; the low byte
BCS TKDONE
DEC OPBYT ; Have we done 2 bytes?
BEQ TKDONE ; Yes, we're done with this token.
BNE TK2BIN ; If not, do next byte
;; We've finished converting a token.
TKDONE: INC TKCNT ; Increment the count of tokens parsed
CMP #$0F ; Have we hit our maximum # of
; operands? (16 max)
BCS EXEC ; Yes, we're absolutely done, no more.
LDA TKND ; No, keep going. Restore Y to end of
TAY ; token position
CPY IBLEN ; Is there more in the buffer?
BCC SKIPSP ; Yes, try to find another token.
;; No, the buffer is now empty. Fall through to EXEC
Comments